

Let’s dive into the paper that laid the foundation for much of recent AI development: Scaling Laws for Neural Language Models.
The paper studies how the performance of AI language models changes as they are scaled up. Their findings led to that competition between AI giants such as OpenAI and Google shifted from building the “smartest” models to purchasing more brain power.
But what is brain power?
In this context, brain power does not mean intelligence in a human sense. It refers to three concrete resources:
- Model size: how many parameters the model has -in practice, how many millions or billions of numbers it can use to store patterns and relationships
- Training data: how much text (and other data) the model learns from
- Compute: how much processing power is used during training -in practice, how many NVIDIA chips you can afford to run, and for how long
Together, these three resources form the engine behind many of the AI models people use every day, such as ChatGPT or Gemini. The three components are tightly linked. If one is limited, the others can often compensate -but only by increasing cost elsewhere.
So how do they build optimal models?
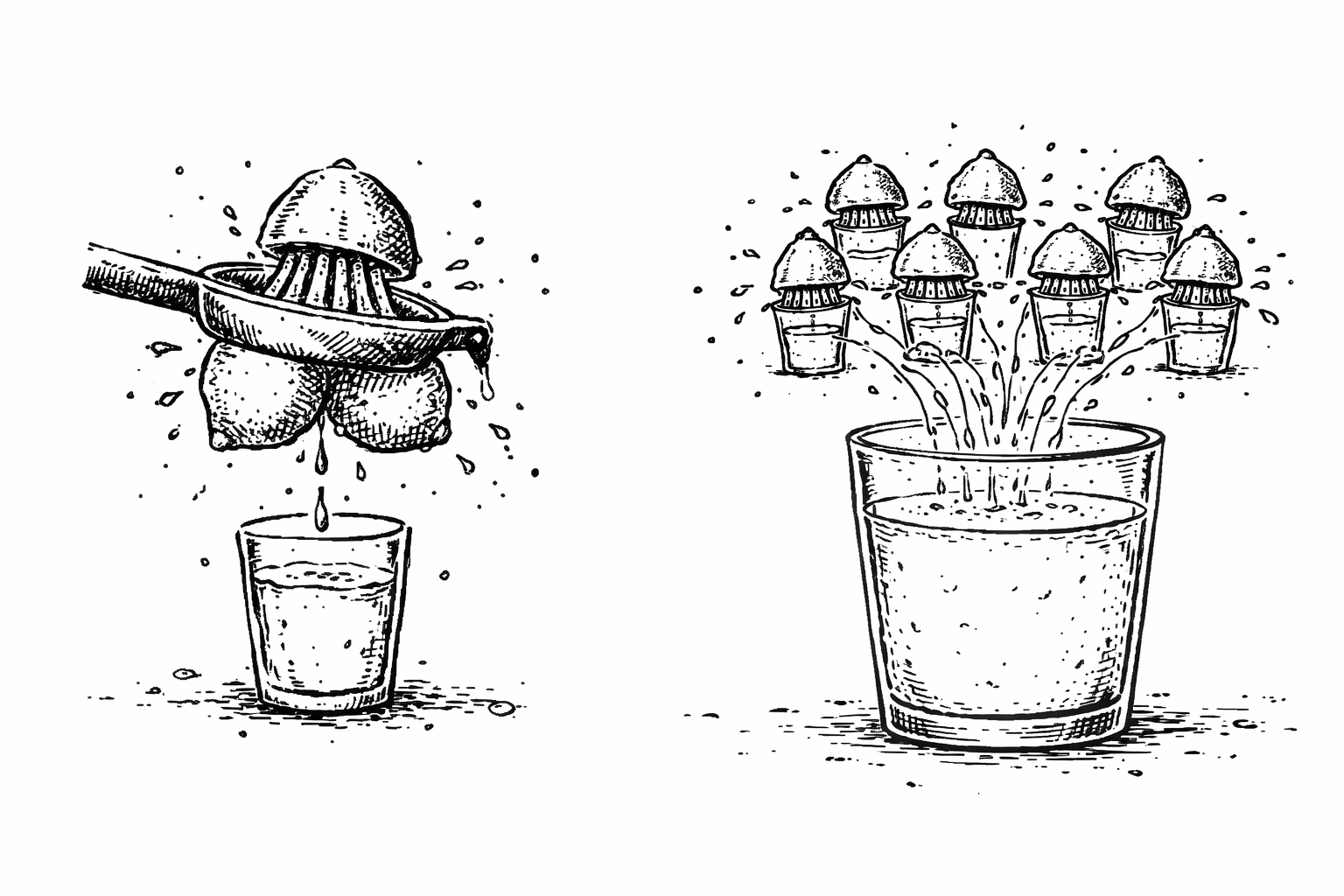
The authors show that model performance improves predictably as resources increase. When these components are scaled, performance follows smooth curves rather than sudden jumps. This predictability allows researchers to estimate in advance how much improvement they are likely to get by spending more resources. I.e. they know that if they buy 4 more lemons, they will get about 100ml of juice.
A second pattern is that scale matters more than clever optimisation. Once a model is reasonably well designed, additional tuning delivers limited gains. Increasing capacity, data, and compute tends to produce more reliable improvements than squeezing extra performance out of smaller models.
What does “optimal” actually mean?
Scaling does not mean increasing everything blindly. The paper shows that there is an optimal balance between model size and training data. Many models are either too large for the data they see or trained on too little data for their size, which leads to wasted compute.
The authors also find that larger models are more sample-efficient. Bigger models learn more from each example and often reach higher performance using fewer training steps than smaller, carefully optimised models. This helps explain why scaling became dominant: it is not just simpler, but often a more efficient way to make progress -even though each improvement comes at a higher cost.
So why don’t we just collaborate and spend trillions on computing and get a mega good AI?
The paper makes clear why this approach runs into limits. Diminishing returns are unavoidable. Each additional unit of compute leads to a smaller improvement than the last. While scaling continues to work, it becomes increasingly expensive, both economically and operationally.
At some point, the question shifts from “can we scale further?” to “is it worth paying for the marginal gains we get?”
Future
This paper laid much of the foundation for today’s large language models. But it also exposes a structural limit: progress that relies primarily on scale becomes increasingly expensive and increasingly inefficient.
We believe this marks the beginning of the next phase of AI development. One where gains come not from buying more compute, but from designing systems that use intelligence more deliberately.
At Thalius, we are working on exactly that shift. More on this soon.